
Introduction
In this project, two years of historical load data were provided, and the goal was to predict the load for the third year. A Convolutional Neural Network-Long Short-Term Memory(CNN-LSTM) model was used for the prediction. In the Kaggle competition, this method achieved significantly above-average prediction accuracy without relying on multiple resubmissions.
Data Cleaning
The training data provided includes load data for the years 2020 and 2021, along with additional features such as precipitation, temperature, wind speed, and humidity.
By analyzing the data, it was observed that some dates had negative load values. Additionally, a review of last year’s Kaggle competition training data revealed that the load values were significantly large, while other features showed minimal variation. This suggests that this year’s data might have been derived from last year’s through linear transformation. However, for last year’s data, the fluctuations accounted for only a minor portion of the overall error, whereas for this year’s data, the occurrence of negative values indicates anomalies resulting from the transformation of last year’s fluctuations.
To address this, all records with negative load values need to be removed at the outset to prevent these anomalies from reducing the prediction accuracy.
Modeling
For the data point corresponding to the $j$-th hour of the $i$-th day, extract the month, day of the week, date, and hour, and denote them as $m_{ij}$, $w_{ij}$, $d_{ij}$, and $r_{ij}$. Next, extract the temperature, humidity, precipitation, and wind speed, and denote them as $h_{ij}$, $u_{ij}$, $p_{ij}$, and $s_{ij}$. At the same time, it is necessary to extract the load data from day $i-1$ and day $i-2$, and denote them as $l1_{ij}$ and $l2_{ij}$. In addition, by using Python's holidays library, determine whether each day is a holiday. If it is a holiday, assign a value of $1$; otherwise, assign $0$. The holiday status is denoted as $n_{ij}$.
Since the task is to predict the load values for the next year, the impact of the month and date is expected to be minimal and therefore was not included in the final features. To capture the short-term load patterns, the load data from the past two days were added as features. To highlight the distinction between holidays and workdays, a feature indicating whether the day is a holiday was introduced. Additionally, to ensure the model focuses on the current day's conditions, only the temperature, humidity, precipitation, and wind speed of the current day were selected as features.
Assume the total number of valid day is $N$, the data finally reshaped into 3D tensor with shape $(N, 24, 9)$, where 24 represents the number of hours in a day, and 9 represents the number of features. For the $j-$th hour of the $i$-th day, this feature can be represented as:
$$x_{ij} = [d_{ij}, r_{ij}, h_{ij}, u_{ij}, p_{ij}, s_{ij}, l1_{ij}, l2_{ij}, n_{ij}]$$
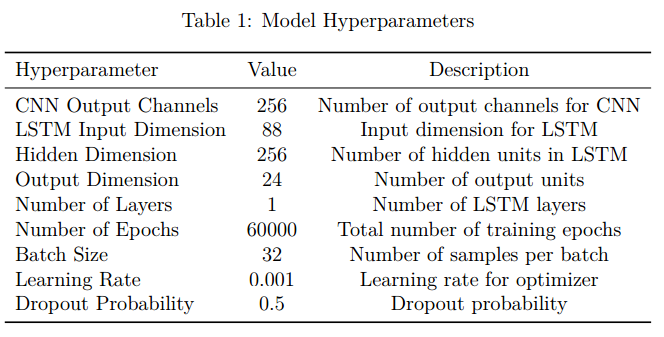
To achieve accurate predictions, a CNN-LSTM model was used. First, the input is passed through a one-dimensional convolutional layer, followed by pooling. Then, it is processed through an LSTM layer, and finally, the output is generated through a fully connected layer. In addition, a dropout layer was used before the fully connected layer to prevent overfitting. The model calculates the loss using Mean Squared Error and is optimized using the Adam optimizer. The hyperparameters of the model are shown in Table \ref{table1}.
Experiments
Since the number of submissions on Kaggle is limited, it is essential to first establish a local evaluation method. Since the provided training data includes data for 2020 and 2021, the testing process uses the 2020 data as the training set and the 2021 data as the test set. This approach enables local model evaluation. Once the model's hyperparameters are finalized, the two years of data are used for training, and the final results are submitted.
All the code was implemented using Python's PyTorch library, and all training was conducted on a laptop. The CPU model is AMD Ryzen 9 7945HX, the GPU is NVIDIA GeForce RTX 4060 Laptop, and the memory size is 32GB.
After 16 attempts, the highest accuracy was achieved on September 26, 2024, with a score of 3.06075. Additionally, on September 27, 2024, after slightly adjusting the number of training epochs, the second-highest accuracy was achieved with a score of 3.07332.
Conclusion
In this project, a CNN-LSTM model was used to predict the load for the third year based on two years of historical data. The model achieved significantly above-average prediction accuracy without relying on multiple resubmissions. Compared to the simple methods in the example code, LSTM has demonstrated strong competitiveness in time series forecasting. With the continuous development of Transformer technology, methods combining Transformer and LSTM for time series prediction are also gradually being explored. These approaches may potentially achieve even higher prediction accuracy.
Code
import numpy as np
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.multioutput import MultiOutputRegressor
from sklearn.metrics import mean_squared_error,mean_absolute_percentage_error
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import MinMaxScaler
import random
import holidays
import os
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(f'Using device: {device}')
# 确保在确定性算法中运行
test = 0
# if test == 1:
# train_data=pd.read_csv('Train data_test.csv')
# else:
# train_data=pd.read_csv('Train data.csv')
train_data=pd.read_csv('Train data.csv')
train_data['DateTime'] = pd.to_datetime(train_data['DateTime'])
train_data['Year'] = train_data['DateTime'].dt.year
train_data['Month'] = train_data['DateTime'].dt.month
train_data['Day'] = train_data['DateTime'].dt.day
train_data['Week'] = train_data['DateTime'].dt.dayofweek
train_data['Hour'] = train_data['DateTime'].dt.hour
#如果某一天的数据的Load为负数,记录这一天的日期,删去所有这一天的数据
negative_load_dates = train_data[train_data['Load'] < 0]['DateTime'].dt.date.unique()
train_data = train_data[~train_data['DateTime'].dt.date.isin(negative_load_dates)]
#往negative_load_dates加入2021年偶数月1日
if test == 1:
negative_load_dates = np.append(negative_load_dates, np.datetime64('2021-02-01'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2021-04-01'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2021-06-01'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2021-08-01'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2021-10-01'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2021-12-01'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2021-02-02'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2021-04-02'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2021-06-02'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2021-08-02'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2021-10-02'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2021-12-02'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2021-02-03'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2021-04-03'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2021-06-03'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2021-08-03'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2021-10-03'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2021-12-03'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2020-02-01'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2020-04-01'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2020-06-01'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2020-08-01'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2020-10-01'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2020-12-01'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2020-02-02'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2020-04-02'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2020-06-02'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2020-08-02'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2020-10-02'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2020-12-02'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2020-02-03'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2020-04-03'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2020-06-03'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2020-08-03'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2020-10-03'))
negative_load_dates = np.append(negative_load_dates, np.datetime64('2020-12-03'))
# 将国庆节标记为1
#获取中国的假日信息
cn_holidays = holidays.China()
# 标记假日信息
train_data['National_Day'] = train_data['DateTime'].dt.date.apply(lambda x: 1 if x in cn_holidays else 0)
print(train_data[['DateTime', 'National_Day']])
train_data['Load_prev_day']=train_data['Load'].shift(24)
train_data['Load_prev_day2']=train_data['Load'].shift(24*2)
train_data['Load_prev_day3']=train_data['Load'].shift(24*3)
pre_day = 0
#Process the data
T_feature_train=np.array(train_data['Temperature']).reshape(-1,24)
H_feature_train=np.array(train_data['Humidity']).reshape(-1,24)
L_feature_train=np.array(train_data['Load_prev_day']).reshape(-1,24)
W_feature_train=np.array(train_data['Week']).reshape(-1,24)
M_feature_train=np.array(train_data['Month']).reshape(-1,24)
P_feature_train=np.array(train_data['Precipitation']).reshape(-1,24)
S_feature_train=np.array(train_data['Wind_speed']).reshape(-1,24)
R_feature_train=np.array(train_data['Hour']).reshape(-1,24)
D_feature_train=np.array(train_data['Day']).reshape(-1,24)
N_feature_train=np.array(train_data['National_Day']).reshape(-1,24)
L2_feature_train=np.array(train_data['Load_prev_day2']).reshape(-1,24)
L3_feature_train=np.array(train_data['Load_prev_day3']).reshape(-1,24)
# 定义滑动窗口函数
def sliding_window(data, window_size):
result = []
for i in range(data.shape[0] - window_size + 1):
window = data[i:i + window_size]
#如果windows中包含negative_load_dates中的某一天continue
if np.isin(window[:,0],negative_load_dates).any():
continue
result.append(window)
return np.array(result)
T_feature_pre = sliding_window(T_feature_train, pre_day + 1)
H_feature_pre = sliding_window(H_feature_train, pre_day + 1)
L_feature_pre = sliding_window(L_feature_train, pre_day + 1)
W_feature_pre = sliding_window(W_feature_train, pre_day + 1)
M_feature_pre = sliding_window(M_feature_train, pre_day + 1)
P_feature_pre = sliding_window(P_feature_train, pre_day + 1)
S_feature_pre = sliding_window(S_feature_train, pre_day + 1)
R_feature_pre = sliding_window(R_feature_train, pre_day + 1)
D_feature_pre = sliding_window(D_feature_train, pre_day + 1)
N_feature_pre = sliding_window(N_feature_train, pre_day + 1)
L2_feature_train = sliding_window(L2_feature_train, pre_day + 1)
#L_feature_pre = np.array(L_feature_pre)
#L_feature_pre[:, 0] = -100
# 合并后两个维度
T_feature_pre = T_feature_pre.reshape(T_feature_pre.shape[0], -1)
H_feature_pre = H_feature_pre.reshape(H_feature_pre.shape[0], -1)
L_feature_pre = L_feature_pre.reshape(L_feature_pre.shape[0], -1)
W_feature_pre = W_feature_pre.reshape(W_feature_pre.shape[0], -1)
M_feature_pre = M_feature_pre.reshape(M_feature_pre.shape[0], -1)
P_feature_pre = P_feature_pre.reshape(P_feature_pre.shape[0], -1)
S_feature_pre = S_feature_pre.reshape(S_feature_pre.shape[0], -1)
R_feature_pre = R_feature_pre.reshape(R_feature_pre.shape[0], -1)
D_feature_pre = D_feature_pre.reshape(D_feature_pre.shape[0], -1)
N_feature_pre = N_feature_pre.reshape(N_feature_pre.shape[0], -1)
L2_feature_train = L2_feature_train.reshape(L2_feature_train.shape[0], -1)
L3_feature_train = L3_feature_train.reshape(L3_feature_train.shape[0], -1)
# 合并为一个三维向量
X_train = np.stack((T_feature_pre, H_feature_pre, L_feature_pre, L2_feature_train, P_feature_pre, S_feature_pre, W_feature_pre, R_feature_pre, N_feature_pre), axis=2)
y_train=np.array(train_data['Load']).reshape(-1,24)
X_train = X_train[1 + 1:]
print(X_train.shape)
y_train = y_train[pre_day + 1 + 1:]
#Data Normalization
scaler_X = MinMaxScaler()
scaler_y = MinMaxScaler()
# 将三维数组展平为二维数组
X_train_reshaped = X_train.reshape(-1, X_train.shape[2])
X_train_nor = scaler_X.fit_transform(X_train_reshaped).reshape(X_train.shape)
y_train_nor = scaler_y.fit_transform(y_train)
X_train_nor = torch.tensor(X_train_nor, dtype=torch.float32)
y_train_nor = torch.tensor(y_train_nor, dtype=torch.float32)
class CNNLSTMModel(nn.Module):
def __init__(self, input_channels, cnn_output_channels, kernel_size, lstm_input_dim, hidden_dim, output_dim, num_layers, dropout_prob=0.2):
super(CNNLSTMModel, self).__init__()
self.hidden_dim = hidden_dim
self.num_layers = num_layers
# 定义CNN层
self.cnn1 = nn.Conv1d(input_channels, cnn_output_channels, kernel_size)
#self.cnn2 = nn.Conv1d(cnn_output_channels, 64, kernel_size)
# 定义LSTM层
self.lstm = nn.LSTM(cnn_output_channels, hidden_dim, num_layers, batch_first=True, dropout=dropout_prob)
# 定义全连接层
self.fc = nn.Linear(hidden_dim, output_dim)
self.pool = nn.MaxPool1d(kernel_size=2)
# 定义Dropout层
self.dropout = nn.Dropout(dropout_prob)
self.relu = nn.ReLU()
self.init_weights()
def init_weights(self):
for name, param in self.lstm.named_parameters():
if 'weight' in name:
nn.init.xavier_uniform_(param.data)
elif 'bias' in name:
nn.init.constant_(param.data, 0)
nn.init.xavier_uniform_(self.fc.weight)
nn.init.constant_(self.fc.bias, 0)
def forward(self, x):
# CNN层
x = x.permute(0, 2, 1) # 调整维度以适应Conv1d输入 (batch_size, input_channels, seq_length)
x = self.cnn1(x)
#x = self.relu(x)
# 池化层
x = self.pool(x)
#x = self.cnn2(x)
#x = self.relu(x)
#x = self.pool(x)
x = x.permute(0, 2, 1) # 调整维度以适应LSTM输入 (batch_size, seq_length, lstm_input_dim)
# 初始化LSTM隐藏状态和细胞状态
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(x.device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(x.device)
# LSTM层
out, _ = self.lstm(x, (h0, c0))
# Dropout层
out = self.dropout(out)
# 全连接层
out = self.fc(out[:, -1, :])
return out
# 超参数
input_channels = X_train_nor.shape[2] # 输入数据的特征数
cnn_output_channels = 256 # CNN输出通道数
kernel_size = 3 # 卷积核大小
lstm_input_dim = 88 # LSTM输入维度 (90 - kernel_size + 1)
hidden_dim = 256
output_dim = y_train_nor.shape[1] # 假设输出维度为1
num_layers = 1
num_epochs = 60000
batch_size = 32
learning_rate = 0.001
dropout_prob = 0.5
# 创建模型、损失函数和优化器
model = CNNLSTMModel(input_channels, cnn_output_channels, kernel_size, lstm_input_dim, hidden_dim, output_dim, num_layers, dropout_prob).to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 假设X_train_nor和y_train_nor已经定义并且在设备上
X_train_nor = X_train_nor.to(device)
y_train_nor = y_train_nor.to(device)
# 训练模型
for epoch in range(num_epochs):
model.train()
optimizer.zero_grad()
# 随机取batch_size个数据进行训练
idx = np.random.randint(0, X_train_nor.size(0), batch_size)
inputs = X_train_nor[idx].to(device)
labels = y_train_nor[idx].to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.6f}')
# 预测
model.eval()
with torch.no_grad():
y_train_pred = model(X_train_nor).cpu().numpy()
y_train_pred = scaler_y.inverse_transform(y_train_pred)
print('ACC:', 1 - mean_absolute_percentage_error(y_train, y_train_pred))
# Read test file
test = 1
X_test=[]
first_day_load = []
test_file_name=['February','April','June','August','October','December']
for name in test_file_name:
if test == 0:
test_data=pd.read_csv('./Test/'+name+'.csv')
else:
test_data=pd.read_csv('./Eval2/'+name+'.csv')
test_data['DateTime'] = pd.to_datetime(test_data['DateTime'])
test_data['Year'] = test_data['DateTime'].dt.year
test_data['Month'] = test_data['DateTime'].dt.month
test_data['Day'] = test_data['DateTime'].dt.day
test_data['Week'] = test_data['DateTime'].dt.dayofweek
test_data['Hour'] = test_data['DateTime'].dt.hour
test_data['National_Day'] = test_data['DateTime'].dt.date.apply(lambda x: 1 if x in cn_holidays else 0)
vars()[name]=test_data # your can use this sentence to generate the variabels 'February','April',..
for name in test_file_name:
test_data=vars()[name]
T_feature_test=np.array(test_data[-24*(pre_day + 1):]['Temperature'])
H_feature_test=np.array(test_data[-24*(pre_day + 1):]['Humidity'])
L_prev_feature_test=np.array(test_data['Load'][-(24+(pre_day + 1) * 24):-24])
first_day_load.append(np.array(test_data['Load'][-24:]))
W_feature_test=np.array(test_data[-24*(pre_day + 1):]['Week'])
M_feature_test=np.array(test_data[-24*(pre_day + 1):]['Month'])
P_feature_test=np.array(test_data[-24*(pre_day + 1):]['Precipitation'])
S_feature_test=np.array(test_data[-24*(pre_day + 1):]['Wind_speed'])
R_feature_test=np.array(test_data[-24*(pre_day + 1):]['Hour'])
D_feature_test=np.array(test_data[-24*(pre_day + 1):]['Day'])
N_feature_test=np.array(test_data[-24*(pre_day + 1):]['National_Day'])
L2_feature_test=np.array(test_data['Load'][-(48+(pre_day + 1) * 24):-24*2])
L3_feature_train=np.array(test_data['Load'][-(72+(pre_day + 1) * 24):-24*3])
#将L_prev_feature_test的前24个元素设置为-100
#L_prev_feature_test = L_prev_feature_test.reshape(-1,24)
#L_prev_feature_test[0,:] = -100
#L_prev_feature_test = L_prev_feature_test.reshape(-1)
X_test.append(np.stack((T_feature_test, H_feature_test, L_prev_feature_test, L2_feature_test, P_feature_test, S_feature_test, W_feature_test, R_feature_test, N_feature_test), axis=1))
X_test = np.array(X_test)
# Inverse normalize
X_test_reshaped = X_test.reshape(-1, X_test.shape[2])
X_test_nor = scaler_X.transform(X_test_reshaped).reshape(X_test.shape)
X_test_nor = torch.tensor(X_test_nor, dtype=torch.float32).to(device)
y_pred_nor = model(X_test_nor).cpu().detach().numpy()
y_pred_test = scaler_y.inverse_transform(y_pred_nor).reshape(1,-1)[0]
if test == 1:
first_day_load = np.array(first_day_load)
first_day_load = first_day_load.reshape(1,-1)[0]
#输出两者的MAPE
print('ACC:', 1 - mean_absolute_percentage_error(first_day_load, y_pred_test))
#Output the Answer
Answer=pd.read_csv('./Test/Answer.csv')
Answer['Load']=y_pred_test
Answer.to_csv('./Test/Answer.csv',index=False)
Comments NOTHING