
获取QQ聊天记录
可以参考以下仓库中的代码
Python
12
由于聊天记录中可能包含不期望出现的内容,可以通过以下代码进行聊天记录删除,例如要删除包含[图片]的聊天记录:
import re
list = []
matchPattern = re.compile(r'[图片]')
file = open('t2.txt',"r",encoding="utf-8")
while 1:
line = file.readline()
if not line:
print("Read file End or Error")
break
elif matchPattern.search(line):
list.pop()
list.pop()
pass
else:
list.append(line)
file.close()
file = open(r't3.txt', 'w',encoding="utf-8")
for i in list:
file.write(i)
file.close()
首先说明,为了保证能够在我的本机运行模型,训练时使用的都是int4的模型,首先我会介绍使用colab免费进行训练的方法,然后介绍使用腾讯云的T4服务器进行训练的方法,从性价比的角度来看,还是推荐使用colab进行训练。
使用colab进行训练
如果我们直接使用仓库中提到的训练方法直接进行运行会出现内存不足的情况。这是由于默认的代码里面使用的是加载完全模型到内存中然后再进行量化的方法,导致需要大于13G的内存才能完成这个操作,免费版能用的内存只有12.7G左右,实测模型在加载到6/8时就出现了内存不足而导致退出。
所以我们可以直接加载量化后的模型来避免内存不足的问题,直接将ptuning/train.sh中改成如下形式:
PRE_SEQ_LEN=128
LR=1.5e-2
CUDA_VISIBLE_DEVICES=0 python3 main.py \
--do_train \
--train_file data/train.json \
--validation_file data/dev.json \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path THUDM/chatglm-6b-int4 \
--output_dir output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 16 \
--gradient_accumulation_steps 1 \
--predict_with_generate \
--max_steps 3000 \
--logging_steps 10 \
--save_steps 500 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN \
这样在下载模型的时候会直接下载量化之后的模型。根据文档保持per_device_train_batch_size和gradient_accumulation_steps的乘积不变,加大per_device_train_batch_size可以加快训练速度。实测这个参数能够跑到T4的80%显存左右。
训练时将数据集放在对应路径下,直接运行
bash train.sh
程序会从huggingface上下载int4的模型并且开始训练
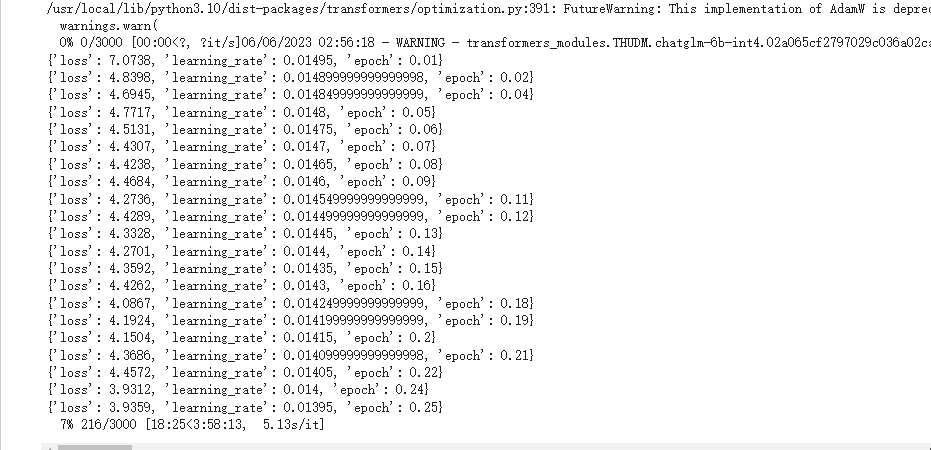
使用腾讯云进行训练
这里需要特别注意,在购买服务器时,需要选择香港的服务器,否则无法从huggingface上下载模型
配置参数和上面的是一样的,在配置参数时需要注意服务器的性能,如果显存占用过低可能导致训练速度过慢
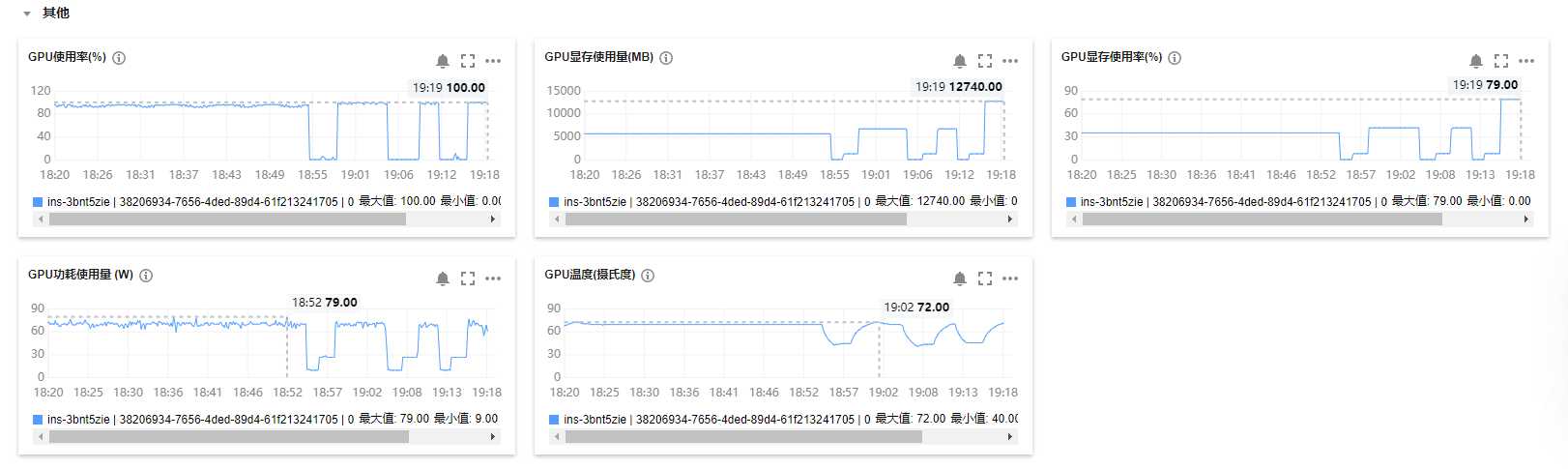
在进行推理时可能会出现报错:
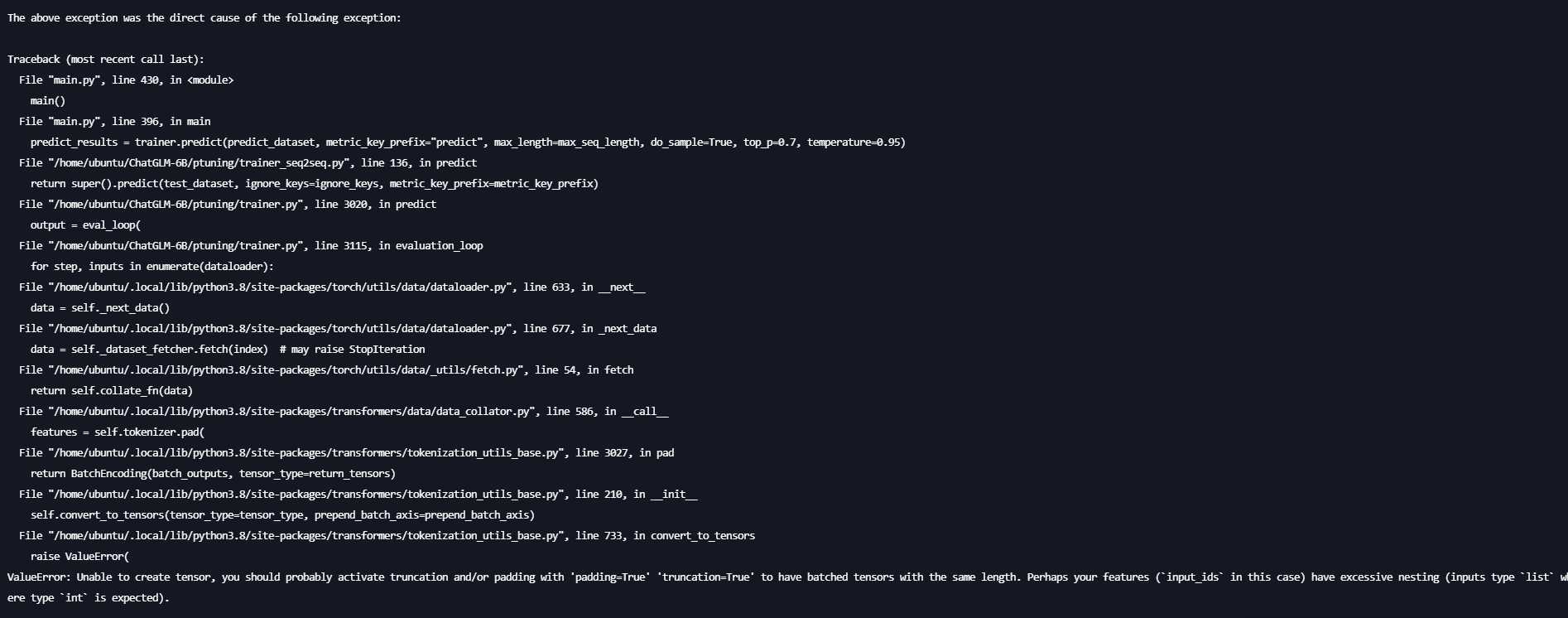
解决方案为修改main.py将
data_collator = DataCollatorForSeq2Seq(
tokenizer,
model=model,
label_pad_token_id=label_pad_token_id,
pad_to_multiple_of=None,
padding=False
)
改为
data_collator = DataCollatorForSeq2Seq(
tokenizer,
model=model,
label_pad_token_id=label_pad_token_id,
pad_to_multiple_of=None,
padding=True
)
如果要在windows下运行训练后的代码可以直接使用
python web_demo.py --model_name_or_path ..\model4 --ptuning_checkpoint output\adgen-chatglm-6b-pt-128-2e-2\checkpoint-500 --pre_seq_len 128
目前训练得到的效果并不是很好,存在非常多的遗忘问题,暂时没有发现有很好的解决方案。
Comments NOTHING